gccemacs
Table of Contents
- New native compiler configure flag
- Update 13 - value/type inference improvements
- Kludging The editor with The compiler - LPC 2020 GNU Tools Track
- Update 12
- Update 11
- Update 10
- Update 9
- Update 8
- Bringing GNU Emacs to Native Code - ELS2020 presentation
- Bringing GNU Emacs to Native Code - proceeding
- Update 7
- Update 6
- Update 5
- Update 4
- Update 3
- Update 2
- Update 1
gccemacs
New native compiler configure flag
As part of the code review process was decided to change the configure flag used to configure the native compiler in the 'feature/native-comp' branch.
As of 42fc752a14 the new configure flag to activate the Elisp
native compilation is --with-native-compilation.
To compile from source:
$ git clone git://git.savannah.gnu.org/emacs.git -b feature/native-comp
$ cd emacs
$ ./autogen.sh
$ ./configure --with-native-compilation
$ make -j$(nproc)
Update 13 - value/type inference improvements
As lately the rate of interesting bugs strictly related to the compiler went drastically down, and as the branch is waiting for code review, I though not to get bored was a good idea to try to re-increase the bug-rate with some new feature :)
Many things progressed on the branch since the last update but I'll discuss mainly the value/type inference related improvements and some of the (immediate and future) implications.
The inference capability of a compiler is the common ground that feeds all other optimizations (unboxing, type checks, constant propagations, etc.), ultimately improving the quality and performance of the generated code.
Inspiration
There was (and still is) a compiler called CMUCL (Carnegie Mellon University Common Lisp) with long roots in history.
CMUCL is based on the Python compiler (named before the programming language), now used also by its "modern" descendant SBCL.
This futuristic compiler introduced for a programming model where not only the compiler is able for diagnosing issues at compile-time, but a dialogue with the programmer can be established in order for the second to improve the code where the compiler could not generate efficient code for some reason. Here a nice blog introducing some of this.
Both CMUCL and SBCL are still known for their powerful type inference capabilities.
Why propagating
We can list some valid reasons why an effective inference engine can be beneficial when compiling a dynamic programming language:
Better compile-time diagnostic
- The compiler might prove that a function will be called with an argument of an incompatible type and raise a warning/error.
Performance
- More type checks can be removed automatically limiting the needs for compiler hints.
- Range propagation can be used to prove effectively if the result of an arithmetic operation will fit in a fixnum.
Generally speaking any pass of the compiler can take decisions based on inferred information on local variables.
Documentation
- Function documentation can be completed with the declared or derived type.
Propagating what?
Before this rework the compiler was able to propagate for each variable only a value or a simple type, and it did not take into account type hierarchy.
Now we aim to be able to propagate what we can express with a Common Lisp style type specifier (well, say a subset).
A type specifier represents a set (finite or not) of values and in Elisp it translates to something like:
integer => an integral number
float => a floating point number
number => an integer or floating point number
atom => all atoms
t => everything
nil => nothing
(function (number) string) => a function taking a number as
argument and returning a string
We can also have type specifiers describing specific values or ranges:
(member foo bar baz) => a symbol among foo bar or baz
(integer 2 4) => an integer among 2, 3, 4
(integer * 1) => an integer less than 1
We can combine all of these with boolean operators as:
(or symbol integer)
(or (integer * 0) (integer 10 *))
(and sequence (not string))
Etc…
Note this notation is capable of identifying set of values as well as the special case of the single one, so this (or its representation) is what we want to handle and propagate inside the compiler!
Function types
We have listed different ways in which a clever inference can be
beneficial, a specific one is the ability to derive function types
automatically. At the moment, I've exposed subr-type and every
(elisp/l) native compiled function will have a type specifier
accessible there.
I've spent quite some time toying and writing tests so here are some examples to give a flavor:
(defun foo (x) x)
Once native compiled one can get foo's type as:
(subr-type (symbol-function #'foo)) ;; => (function (t) t)
(defun foo (x) (if x 1 3)) ;; => (function (t) (or (integer 1 1) (integer 3 3)))
(defun foo (x) (if x 'foo 3)) ;; => (function (t) (or (member foo) (integer 3 3)))
Integer range propagation
(defun foo (x) (when (> x 3) x)) ;; => (function (t) (or null float (integer 4 *)))
Constant propagation
(defun foo (x) (let ((y 3)) (when (> x y) x))) ;; => (or null float (integer 4 *))
(defun foo (x) (when (> 10 x 3) x)) ;; => (function (t) (or null float (integer 4 9)))
Logior is known to have (or marker integer) as parameters
(defun foo (x y) (setf bar (logior x y)) y) ;; => (function (t t) (or marker integer))
The range is propagated across the + function.
(defun foo (x y) (when (and (> x 3) (> y 2)) (+ x y))) ;; => (function (t) (or null float (integer 7 *)))
(defun foo (x y z i j k) (when (and (< 1 x 5) (< 1 y 5) (< 1 z 5) (< 1 i 5) (< 1 j 5) (< 1 k 5)) (+ x y z i j k))) ;; => (function (t) (or null float (integer 12 24)))
(defun foo (x) (if (not (integerp x)) x (error "Ops")))) ;; => (function (t) (function (t) (not integer)))
(defun foo (x) (cond ((not (integerp x)) (error "Ops")) ((> x 100) 'big) ((< x -100) 'small) (t x))) ;; => (function (t) (or (member big small) (integer -100 100)))
Some SBCL comparison
Despite trying to provide similar inference capabilities, the Emacs native compiler and Python differ per construction and used internal representation. This can lead to different and interesting results.
(defun foo (x) (let ((y 'bar)) (setf y 100) (if x (setf y 1) (setf y 2)) y))
In this case SBCL forecasts as return type (OR (MEMBER
COMMON-LISP-USER::BAR) (INTEGER 100 100) (INTEGER 1 2)), note that
both bar and 100 indeed can never be returned. Apparently
when local variables are reassigned Python is falling back on
listing all possible values that a variable may assume during
execution.
This might be quite a relevant limitation for a not very functional programming language as Elisp.
In contrast in the Emacs native compiler the propagation happens in
the SSA lattice with precise analysis of each variable at any point
of the control flow graph, the forecasted return type is then only
(integer 1 2).
Another interesting case is code like the following:
(defun foo (x) (unless (or (eq x 'foo) (eql x 3)) (error "Ops")) x)
SBCL forecasts a return type of T while we identify that the
function can only return (or (member foo) (integer 3 3)).
This is not to say that Emacs compiler is superior, there's still a lot to do and I'm sure there are many corners where Python does better, but I believe being based on a "modern" representation as SSA is a solid foundation to start with.
For who's interested this blog discuss more in depth some of Python's limitations.
How does it work
Where does the compiler get the value/type information to be propagated in the control flow graph?
- For each conditional branch testing a value produced by
eqeqlequal=dedicated constraints are placed in the target basic blocks to express the result. Constraining a variable translates in a set-like operation as union, intersection or negation. - Similarly we constrain integer ranges when testing with
>>=<<=. - Again we constrain variables for type when they are tested using a known type predicate.
- We propagate integer ranges across arithmetic functions (ATM
+and-). Read(1+ (integer 1 2)) => (integer 2 3) - We rely on known function type specifiers for corresponding function return values.
- Similarly we can constrain function arguments. For example, after
calling
(int-to-string x)in the CFG we can assumexbeing anumberbecauseint-to-stringtype is know to be(function (number) string)).
So yes, to feed the inference engine I enjoined writing ~300 type
specifiers for built-in and pure functions. These ATM are in
comp-known-type-specifiers.
The compiler cannot rely on other function types derived by the compiler as these indeed might be redefined.
Limitation and final words
The code went progressively in the last couple of months, still a number of things needs to be done:
- Propagation is at the moment disabled on functions catching non local exists.
- Still need to expose these type specifiers through
cl-the. - There's currently no API to manually declare (declaim?) function types, same parameter type declaration inside functions has to be done.
- The system is currently limited to built-in types, not by construction but needs to be done. I think this should give sensible speed-ups especially for code with many structure slot accesses.
- No diagnostic is emitted based on inferred value/types.
On my system ATM I have about 4000 functions loaded where the
derived return type is something more interesting than t, this is
about the 20% of the total. Such number might increase in the
future if the system improves, if we describe more primitives to
the compiler and/or more functions are declaimed by users and if
more dynamic code get ported into lexical.
So yeah this should be the foundation for other optimizations to come (Ex. unboxing).
Ah! Happy new year :)
Kludging The editor with The compiler - LPC 2020 GNU Tools Track
This year unfortunately the GNU Tools Cauldron was canceled due to the COVID situation. In place of that a GNU Tools Track has been hosted at Linux Plumbers Conference 2020.
Here is the recording of the presentation I gave the 27th of August for the GNU tool-chain developers about this project:
- Streaming on toobnix.org (PeerTube instance).
- OGV format here.
- Slides in pdf format here.
Update 12
Some retrospective on the last 5 weeks activities:
Fast bootstrap as default
Fast bootstrap is now active by default. A new control has been
added called NATIVE_FULL_AOT to force full Ahead-of-Time native
compilation of all Emacs. This supersedes NATIVE_FAST_BOOT and
effectively works as this last being negated.
To force full Ahead-of-Time compilation: make NATIVE_FULL_AOT=1.
Exposing compiler type hints
In the seek of making compiler type hints usable I've done some initial work to expose these through the available Common Lisp extensions we have.
cl-the now understands fixnum and cons.
As cl-the decides to emit the type check based on
cl--optimize-safety and cl--optimize-speed I needed a way to
synchronize the latter with comp-speed and to have these
effectively set. I added cl-optimize as a defun declaration as
this is function context aware.
I've also added a benchmark called inclist-type-hints to the
elisp-benchmarks that re-implements the original inclist making
use of type hints.
As an example this what it looks likes:
(defun elb-inclist-th (l) (declare (cl-optimize (speed 3) (safety 0))) (prog1 l (while l (let ((c (cl-the cons l))) (cl-incf (cl-the fixnum (car c))) (setq l (cdr c))))))
On my machine the original inclist benchmark runs in 1.59s and
the new inclist-type-hints in 0.75s that is about twice as
fast.
New libgccjit entry point
I've up-streamed in GCC the libgccjit support for static initialized arrays and installed the corresponding code on the Emacs side to make use of this feature when available.
This new entry point will come with GCC 11 and as we discussed in
Compile time this should help marginally with the current Emacs
load time and in the (far) future may allow us for removing the
current workaround we have in Emacs. That said I also suspect may
become crucial the day we get a faster de/serializer and we make
use of it the .eln load machinery.
New primitive trampoline mechanism
Sweets come lasts. This activity tackle one of the last source of incompatibility we had against the vanilla implementation that was primitive advising.
As you may know the native compiler tries to emit direct calls to
primitive functions to avoid going through the funcall
trampoline, and it tries to do that for every primitive including
the ones without a dedicated op-bytecode.
As this is extremely effective performance wise unfortunately it made advice uneffective for all primitive functions called from native compiled Lisp.
Now the manual warn against the primitive advice practice for two reasons:
- Primitives maybe called directly from C and there's no way the advice will be effective in that case.
- Circularity with the advice mechanism.
The manual does not mention that (as technically it falls into the
first point) but has to be noted that the byte interpreter will
call directly all primitives with a dedicated op-bytecode again
ignoring advices. Therefore as an example advising function +
will be effective only on interpreted Lisp but not on byte-compiled
one!
Now apparently advising primitives is a very bad practice and no one should go for it, but in reality I can tell you that a ton of packages just do that as typically works for many primitives.
The current workaround was to have a list of primitives commonly advised and use this to prevent optimizations on these. Quite a weak approach as regularly some package showed-up advising some primitive not in the list.
The following mechanism is what we came-up with to fix the problem,
say we want to advice the delete-file primitive:
A trampoline function similar to the following is synthesized.
(defun --subr-trampoline-delete-file (filename &optional trash) (funcall filename trash))
- This function is native compiled (without performing
funcalltrampoline removal!). Note also that the expose ABI is exacly the same of the original primitive. - Once this function is loaded the function pointer to this function is used to replace the primitive one in the function link table.
The result of this procedure is that each newly activated function
will use the trampoline in place of the original primitive and the
trampoline will execute the call going through funcall making
the advice effective!
This works so well that in-fact now is even possible to advice
effectively what wasn't effective in byte-code (ex the +
function). But hey, don't try this a home!
Compiled trampolines are stored in the eln cache directory and re-used for following sessions without requiring further compilations.
Integration, turning the buoy
Now what's so important about the last item? Well just this was the last one in my list of compatibility issues!
This obviously doesn't mean that now it's all perfect or done, but it means that if a package is not behaving correctly I'll be very interested into looking into it because a priori I've no idea why it should not work correctly.
Integrating the native compiler with Emacs has been a very long and non straight forward task, so I feel quite relieved thinking the most is done and things are in the right direction.
A question raise that is "what's next"? Here my plans:
- Clean-up what's left on the bug tracker and have a look for some code clean-up.
- Collect any feedback regarding some requirement that may be left for upstreaming.
- Happily restart working in the compiler itself to improve it further.
Looking forward!
Update 11
This update is changing the eln files positioning on the
file-system and the compilation triggering and load mechanism. All
of this in aim of making all the native compilation business
completely transparent to the user.
As a consequence all you need to know is that once compiled having
configured with --with-nativecomp during normal use everything
should now happen automatically, dot.
Still here? how it works:
Compilation triggering and load mechanism
Deferred compilation is now enabled by default, therefore is not
anymore necessary to set comp-deferred-compilation manually.
When a .elc file is being loaded if a suitable .eln file is
found in one of the eln-cache directories this is loaded instead.
Otherwise the file is compiled asyncronously and its definitions are
swapped once finished with that.
I've removed .eln from load-suffixes as loading native code is
not supposed to be manually done by the user. This has also the
positive side effect to reduce the number of files we search for
while performing a load.
eln file placement
A new global variable is defined comp-eln-load-path. By default
this is a list of two eln-cache directories. On my installed
Emacs looks like:
("~/.emacs.d/eln-cache/" "/usr/local/libexec/emacs/28.0.50/x86_64-pc-linux-gnu/eln-cache/")
The first one is in use by the user for new compilations while the
second one is for .eln files compiled during the build process.
Each eln-cache directory has a structure of this kind:
~/emacs$ tree eln-cache/
eln-cache/
└── x86_64-pc-linux-gnu-918495e2956ca37e
├── abbrev-a99d112c152dc4841918bf4ba7134a3345ff6ba5ae5548b6ad8c0098b169ddf5.eln
├── autoload-485c4a0aa35fee71d840229c24a2663ea75ab150df53c33d65bb19c50d864430.eln
├── backquote-613030c141e05318757ad8d32f6876fa6a7dc493d67ed5b940fa5c484739d955.eln
...
The additional directory layer inside eln-cache it's used to
disambiguates triplet and Emacs configuration. Each .eln file
has a name constructed with an hash to match the original source
file.
New compiled files are deposed always in the first entry of
comp-eln-load-path.
You can delete any eln-cache folder as files will be recompiled
when needed with the exception of the last entry in
comp-eln-load-path. This is to be considered the eln system
cache directory and contains files necessary for a native compiled
Emacs to start-up.
You can still monitor if you wish the compilation activity in the
*Async-native-compile-log* buffer. If you want to check
interactivelly that a function is effectively native compiled you
can still use C-h f or M-x disassemble.
Update 10
Dynamic scope support
About three weeks ago I've merged support for native compiling dynamic scoped Elisp. After some (expected) necessary fixing now every thing seems to be working correctly.
The native compiler is now able to compile every .el file given
as input and the amount of native code compiled in Emacs is roughly
doubled.
More optimizations
"It's a long way to the top…" and the same is for completing this integration job. So I took quick digression back into performance.
This interesting discussion lead to a broader and unified definition of which functions in Emacs Lisp are pure. This advantage both byte and native compiler but the second one especially given the nature of its propagation engine.
Having now at disposal a bigger set of primitives pure functions to begin with and having implemented the mechanism to fetch function pure declaration, I thought was interesting to implement a small inter-procedural analysis pass to infer automatically other pure functions not explicitly declared as such.
Given pure functions when possible gets executed in the compile
time making ineffective subsequent redefinitions, this pass is
gated at speed 3.
It was fun to see that three of the u-benchmarks gets completely optimized out and are executed now in zero time.
| test | b0f683ec16 (2w ago) | 907618b3b5 (now) | |
|---|---|---|---|
| tot avg (s) | tot avg (s) | perf uplift | |
| bubble-no-cons | 2.36 | 2.39 | 0.99x |
| bubble | 1.65 | 1.52 | 1.09x |
| dhrystone | 2.53 | 2.38 | 1.06x |
| fibn-rec | 2.10 | 0.00 | ---- |
| fibn-tc | 1.40 | 0.01 | 140.00x |
| fibn | 4.21 | 0.00 | ---- |
| flet | 2.65 | 2.44 | 1.09x |
| inclist | 1.58 | 1.59 | 0.99x |
| listlen-tc | 0.14 | 0.14 | 1.00x |
| map-closure | 6.29 | 6.05 | 1.04x |
| nbody | 1.64 | 1.49 | 1.10x |
| pcase | 1.82 | 1.75 | 1.04x |
| pidigits | 6.09 | 6.76 | 0.90x |
| total | 34.45 | 27.10 | 1.27x |
One could argue that these u-benchmarks are too simple and now we need more complex ones, and yes he's right :)
Update 9
Compile time
Compile time is reduced of about a factor 5!
I was suspecting part of the issue of the considerable compile time had to be related to how we stored constant objects into the compiled code. This assumption was coming from the observation that compilation units with a lot of objects had higher compile times.
I wrote a GCC patch to enable static data initialization with
libgccjit and when I first tested it I was surprised in how
faster compiling the branch was.
As a counter measure we came-up with a work-around using string literals so we are not dependent on a new GCC to come. The workaround has performance very close to the Emacs modified for my patched GCC I've experimented with.
On my dev machine I native compile all Emacs in ~60min total CPU time (to be divided on multiple cores). That means I have it ready in ~6min! Considering the number of bootstraps I do for development I'm very satisfied about that to say the least.
As a reference the full bootstraps of the branch without native compilation takes about on the same machine ~25min total CPU time. This implies that deferred-compilation is now not anymore a mandatory to have mitigation but a nice compelling to automatically compile packages.
Also memory consumption during compilation benefits from that. Now is possible to compile on 32bit systems all Emacs at speed 2 and native compilation should be much more accessible for constrained systems.
Lambda performance
Given now anonymous lambdas are compiled I've invested some time optimizing the middle end to take advantage of that and took some simple measures.
There are few interesting point specific to lambda compilation.
The original lambdas definition is kept through the whole pipeline of the compiler so they can be executed in the compile time if necessary, eventually the native compiled version replace it only in the generated code.
Being lambdas objects they are transparently propagated within the SSA lattice. This implies that in forms like the following
(let ((f (lambda (x) (1+ x)))) ... (funcall f y))
the compiler is able to prove that the first argument of funcall
is the lambda defined above. The native compiler will then remove
the call to funcall and rewrite it as a direct call to the
compiled lambda.
Given lambdas are 'immediate objects' that don't have to go through name resolution as conventional functions this optimization is always safe to be performed and does not have to be gated at speed 3.
funcall removal, as we have seen in the past, can be very
beneficial for performance but also enable GCC for inlining the
lambda if convenient.
Also worth noting that the above snippet is about what cl-flet
and other macros expand in, so hopefully this work benefits them
all. Compiling the whole Emacs I'm counting 17744 lexical scoped
lambdas now compiled.
To measure the effect of these modification I've added three
u-benchmarks to elisp-benchmarks. They leverage local functions
using cl-flet, pcase and closures.
I compared the results of the current feature/native-comp with
9daffe9cfe from about 4 weeks ago with no lambda support.
| test | bytecode | native-comp | rel | native-comp | rel |
|---|---|---|---|---|---|
| no lambda | today | ||||
| bubble-no-cons | 9.56 | 2.71 | 3.5x | 2.84 | 3.4x |
| bubble | 8.13 | 1.96 | 4.1x | 1.99 | 4.1x |
| dhrystone | 7.25 | 3.05 | 2.4x | 3.06 | 2.4x |
| fibn-rec | 6.14 | 2.41 | 2.5x | 2.47 | 2.5x |
| fibn-tc | 5.49 | 1.60 | 3.4x | 1.79 | 3.1x |
| fibn | 9.72 | 5.10 | 1.9x | 4.74 | 2.1x |
| flet | 10.20 | 4.46 | 2.3x | 2.89 | 3.5x |
| inclist | 12.90 | 1.56 | 8.3x | 1.57 | 8.2x |
| listlen-tc | 6.06 | 0.20 | 30.3x | 0.19 | 31.9x |
| map-closure | 7.81 | 7.68 | 1.0x | 7.97 | 1.0x |
| nbody | 10.18 | 1.92 | 5.3x | 1.96 | 5.2x |
| pcase | 10.09 | 2.54 | 4.0x | 2.13 | 4.7x |
| pidigits | 11.38 | 7.00 | 1.6x | 7.74 | 1.5x |
| total | 114.91 | 42.17 | 2.7x | 41.34 | 2.8x |
Most of tests are not affected including map-closure. Closures
are still not native compiled and more work will be required for
that.
flet is about 50% faster and also pcase shows some measurable
improvement.
Windows support
The patches for the Windows support has been merged, also Nico has
upstreamed the support on the libgccjit side, thanks!
Update 8
Almost two months passed since I wrote the last update but really a lot happened.
Apparently the ELS paper and its presentation gave some exposure to the project and with that I got quite some feedback! As a consequence a lot of small fixing and improvements happened in addition to the following points:
32 bit support
I ported and tested the branch on X86_32 for both wide-int and
non wide-int configuration. This implies that the back-end can
now generate code with the tag bits in MSB or LSB position
according to the configuration. Still I managed to boot only with
NATIVE_FAST_BOOT or at comp-speed 0 due to the 2GB addressable
memory limit that we still violate (See Optimizing the build).
Lazy documentation load
A mechanism for lazy loading the function documentation from the
.eln files is now in place. This allow for reducing the number
of unnecessary objects that the Garbage Collector has to traverse.
Optimizing the build
Reworking the code generation for 32bit I've measured a reduction of the compilation time of ~15%.
Following that I received an excelent report from Kévin Le Gouguec on memory consumption and compile-time analyzing the compilation process.
As follow-up on that now the leim/ sub-folder is by default not
compiled. Being these files data and not code it should not affect
performance.
The overall compile time is then reduced respect to the original
one by a factor two. I can now build on my compile-box a full
Emacs at speed 2 in ~47min, this to be compared with the original
~100min on the same machine for the branch at the state of Update 7.
The maximum memory used for the build (single thread speed 2) now
peaks around 3GB while compiling Org and as a consequence is
still out of the addressable limit for 32bit systems. This will be
a subject of optimization for the future.
Operating system support
Free BSD
I had a run on Free BSD on X86_64 and it worked out.
Mac OS
There has been quite some discussion on the web on how to build for Mac Os. This is reported to work fine and here are some build instructions (bootstrap at speed 3 is not recommended), here the original discussion.
Windows
A series of patches has been posted for Windows by Nicolas Bértolo so work is ongoing and Windows support is to come!
GNU/Linux distribution specific discussions
New customizes
Is now possible to selectively exclude files from being native
compiled by deferred compilation using
comp-deferred-compilation-black-list.
Similarly but for bootstrap comp-bootstrap-black-list has been added.
Lambdas compilation
This is really the big boy that kept me busy for the last almost 3 weeks.
Now the native compiler is finally compiling also anonymous lambdas.
Before pushing the branch I tested it at my best, I hope there are no regressions. Also I still have to complete the tuning of the compiler to fully take advantage of that but this is a major improvement.
I'd like to come back on this with a post to discuss it better because it should have measurable performance implications.
Bringing GNU Emacs to Native Code - ELS2020 presentation
This is the recording of the presentation I gave for the European Lisp Symposium 2020 about the proceeding titled "Bringing GNU Emacs to Native Code".
You can find it for download here in OGV file video format or here for streaming on toobnix.org (a PeerTube instance).
The slides are here for download.
Bringing GNU Emacs to Native Code - proceeding
I very pleased to announce that the proceeding Luca Nassi, Nicola Manca and me worked on about this project has been accepted for the European Lisp Symposium 2020.
Pdf here https://doi.org/10.5281/zenodo.3736363 (direct link).
Update 7
Native compile async update
The number of parallel compilation threads used by
native-compile-async is now controlled by the
comp-async-jobs-number customize.
This uses by default half of the available CPUs (or at least one) or can be tuned manually.
Is possible to change dynamically this while compiling and have the system converging to the desired value.
Deferred compilation
When comp-deferred-compilation is non nil and a lexically bound
.elc defining functions is loaded then an asyncronous native
compilation is queued for it. When this is finished function
definitions in the compilation unit are automagically swapped for
the native one.
This works similarly to an asyncronous jit compiler but still retains the advantage of being able to save to disk. Simply reloading the compiled output at the next startup saves from unnecessaries recompilations.
This is mechanism is general and works very well for handling transparently package compilations.
Fast bootstrap
Starting from the observation that native compiling all Emacs can be overkill and takes a long time I've added to the build system the possibility to native compile exclusively the compilation unit used for producing the dumped Emacs image. All other lisp files in this case are byte-compiled conventionally.
It can be used as follow:
make NATIVE_FAST_BOOT=1
The compile time for a bootstrap at speed 2 in this case goes down one magnitude order from ~1000m to ~100m CPU time (to be divided by the machine parallelism used).
The produced Emacs if used with comp-deferred-compilation enabled
will then native compile only the used files while having the
system immediately already usable. Essentially Emacs will
asynchronously compile and load itself while already running.
In case you want to try this remember that Emacs will compile the
file being loaded only when comp-deferred-compilation is non nil,
so make sure this is set very early into your .emacs.
CI integration
On the Emacs CI for every push we now test for bootstrap the stock configuraiton and the native compiled one at speed 0 1 2 (1 appears to be broken). Thanks Michael for suggesting this and explaining how to configure it.
Others
Received the first patch!! Thanks Adam.
Somebody apparently had it running on Windows 10 hacking libgccjit! (Chinese):
http://www.albertzhou.net/blog/2020/01/emacs-native-comp.html
OSX apparently works but only speed 0 for now:
https://gist.github.com/mikroskeem/0a5c909c1880408adf732ceba6d3f9ab
I believe next is more debugging and start thinking about make install.
Update 6
Better memory usage
A better allocation strategy for relocated objects is now in place. This should benefit memory usage and (as a consequence) GC time.
Multi-arch multi-conf support
Now different Emacs configurations and/or architectures can build on the same Lisp code base.
eln files are compiled in a specific sub-folders taking in
account host architecture and current Emacs configuration to
disambiguate possible incompatibilities.
As example a file .../foo.el will compile into something like
.../x86_64-pc-linux-gnu-12383a81d4f33a87/foo.eln.
I've updated the load and 'go to definition' mechanisms to support this, so should be totally transparent to the user.
The same idea applies to all compilations meaning main build process as packages when gets built.
Optimize qualities
Optimize qualities (read compilation flags) are now stored in every
eln file. Is now possible to inspect them as:
(subr-native-comp-unit (symbol-function 'org-mode)) #<native compilation unit: .../emacs/lisp/org/x86_64-pc-linux-gnu-12383a81d4f33a87/org.eln ((comp-speed . 2) (comp-debug . 0))>
Docker image
I've made a docker image for people intrested in trying this branch out without having to compile and/or install Emacs and libgccjit.
https://hub.docker.com/r/andreacorallo/emacs-nativecomp
I'll try to keep it updated. Also I plan to setup a small CI to test that the latest GCC does not break with our build.
Update 5
New function frame layout
The variables layout in the generated code has been redesigned. Now every call by reference gets its own unique array to be used by the arguments. This should generate slightly better code limiting spilling.
Doese not impact on compilation time, but produced binaries (as expected) are slightly smaller.
speed 2 stable! New default
After some interesting bug fixing is now 2 weeks that a colleague
and me are using for everyday production a native compiled Emacs
boostrapped at speed 2. So far we have seen no crashes.
I consider having speed 2 stable a very major achievement.
As a consequence with the today push I'm setting speed 2 as
default. This brings up compilation time to ~7h CPU time on my
laptop (to be divided by the number of CPUs) for a boostrap
starting from a clean repository.
I'll look in the future how to mitigate that but is important to test with optimizations engaged.
Self TCO
Also a pass to perform self Tail Call Optimization has been
added. This is for now active only at speed 3.
Traditionally Emacs Lisp does not perform TCO. This pass should give more support to the programmer if a functional programming style is adopted.
Update 4
As of today gccemacs no longer exists as independent project and
its codebase is developed on the official Emacs repository
git://git.sv.gnu.org/emacs.git under the feature/native-comp
branch.
To bootstrap it:
./autogen.sh ./configure --with-nativecomp make -JX
(substitute X with the number of your cpus).
All of this is just exciting!
Update 3
Here are some notes on the implementation of the compilation process
and load mechanism for a simple compilation unit test.el with the
following content:
;;; -*- lexical-binding: t -*- (defun foo (x) (let ((i 0)) (while (< i x) (bar i) (message "i is: %d" i) (setq i (1+ i)))))
Native compilation process internals (an example)
Compilation is invoked with:
(native-compile-async "/path/to/test.el")
In this case the following compilation parameters has been used:
comp-speed2comp-debug1comp-verbose3
Note: all the dumped data-structures presented below have been
collected from the *Native-compile-Log* buffer that was created
because of the comp-verbose value.
The compilation goes through the following passes:
comp-spill-lap (comp.el:452)
comp-spill-lap will first run the conventional byte-compiler.
This has been modified to accumulate all top level forms into
byte-to-native-top-level-forms.
The function foo will be hold in an instance of structure
comp-func. This has various slots but the one we are more
interested in is the LAP one. Here the its content:
(byte-constant 0 . 0)
(TAG 1 . 2)
(byte-dup)
(byte-stack-ref . 2)
(byte-lss . 0)
(byte-goto-if-nil-else-pop TAG 23 . 3)
(byte-constant bar . 1)
(byte-stack-ref . 1)
(byte-call . 1)
(byte-discard)
(byte-constant message . 2)
(byte-constant "i is: %d" . 3)
(byte-stack-ref . 2)
(byte-call . 2)
(byte-discard)
(byte-dup)
(byte-add1 . 0)
(byte-stack-set . 1)
(byte-goto TAG 1 . 2)
(TAG 23 . 3)
(byte-return . 0)
This is effectively the main input for the function compilation process.
comp-limplify (comp.el:1208)
Next pass is comp-limplify, its main responsibility is to
generate the LIMPLE representation. After this transformation the
function will be a collection of basic blocks each of these
composed by LIMPLE insns.
The format of every LIMPLE insn is a list (operator operands) where
operands can be instances of comp-mvar (comp.el:276) or directly
Lisp objects with a meaning that depends on the operator itself.
- Main LIMPLE operands
Here's a quick presentation of some LIMPLE operands.
(set dst src)Copy the content of the slot represented by the
m-varsrcinto the slot represented bym-varb.(setimm dst imm)Similar to the previous one but
immis a Lisp object known at compile time.(jump bb)Unconditional jump to basic block
bb(cond-jump a b bb_1 bb_2)Conditional jump to
bb_1orbb_2after having comparedaandb.(call f a b ...)Call subr
fwith m-varsabetc as parameters.(callref f a b ...)Same as before but for subrs with signature C
(ptrdiff_t nargs, Lisp_Object *args).(comment str)Include annotation
stras comment into the.elndebug symbols (comp-debug> 0).(return a)Return using as return value the content of the slot represented by
a.(phi dst src1 src2 ... srcn)Propagates properties of m-vars
src1…srcnintom-vardst.
Every
comp-funcstructure has the collection of basic blocks into theblocksslot.All functions are kept into the compilation context
comp-ctxtwithin thefuncs-hslot.This is the representation of LIMPLE for the compilation unit after
comp-limplifyhas run:Function: foo <entry> (comment "Lisp function: foo") (set-par-to-local #s(comp-mvar 0 nil nil nil nil nil) 0) (jump bb_0) <bb_0> (comment "LAP op byte-constant") (setimm #s(comp-mvar 1 nil nil nil nil nil) 0 0) (jump bb_1) <bb_1> (comment "LAP TAG 1") (comment "LAP op byte-dup") (set #s(comp-mvar 2 nil nil nil nil nil) #s(comp-mvar 1 nil nil nil nil nil)) (comment "LAP op byte-stack-ref") (set #s(comp-mvar 3 nil nil nil nil nil) #s(comp-mvar 0 nil nil nil nil nil)) (comment "LAP op byte-lss") (set #s(comp-mvar 2 nil nil nil nil nil) (callref < #s(comp-mvar 2 nil nil nil nil nil) #s(comp-mvar 3 nil nil nil nil nil))) (comment "LAP op byte-goto-if-nil-else-pop") (cond-jump #s(comp-mvar 2 nil nil nil nil nil) #s(comp-mvar nil nil t nil nil nil) bb_2 bb_3) <bb_3> (comment "LAP TAG 23") (comment "LAP op byte-return") (return #s(comp-mvar 2 nil nil nil nil nil)) <bb_2> (comment "LAP op byte-constant") (setimm #s(comp-mvar 2 nil nil nil nil nil) 2 bar) (comment "LAP op byte-stack-ref") (set #s(comp-mvar 3 nil nil nil nil nil) #s(comp-mvar 1 nil nil nil nil nil)) (comment "LAP op byte-call") (set #s(comp-mvar 2 nil nil nil nil nil) (callref funcall #s(comp-mvar 2 nil nil nil nil nil) #s(comp-mvar 3 nil nil nil nil nil))) (comment "LAP op byte-discard") (comment "LAP op byte-constant") (setimm #s(comp-mvar 2 nil nil nil nil nil) 3 message) (comment "LAP op byte-constant") (setimm #s(comp-mvar 3 nil nil nil nil nil) 4 "i is: %d") (comment "LAP op byte-stack-ref") (set #s(comp-mvar 4 nil nil nil nil nil) #s(comp-mvar 1 nil nil nil nil nil)) (comment "LAP op byte-call") (set #s(comp-mvar 2 nil nil nil nil nil) (callref funcall #s(comp-mvar 2 nil nil nil nil nil) #s(comp-mvar 3 nil nil nil nil nil) #s(comp-mvar 4 nil nil nil nil nil))) (comment "LAP op byte-discard") (comment "LAP op byte-dup") (set #s(comp-mvar 2 nil nil nil nil nil) #s(comp-mvar 1 nil nil nil nil nil)) (comment "LAP op byte-add1") (set #s(comp-mvar 2 nil nil nil nil nil) (call 1+ #s(comp-mvar 2 nil nil nil nil nil))) (comment "LAP op byte-stack-set") (set #s(comp-mvar 1 nil nil nil nil nil) #s(comp-mvar 2 nil nil nil nil nil)) (comment "LAP op byte-goto") (jump bb_1) Function: top-level-run <entry> (comment "Top level") (set-par-to-local #s(comp-mvar 0 nil nil nil nil nil) 0) (call comp--register-subr #s(comp-mvar nil nil t foo nil nil) #s(comp-mvar nil nil t 1 nil nil) #s(comp-mvar nil nil t 1 nil nil) #s(comp-mvar nil nil t "F666f6f_foo" nil nil) #s(comp-mvar nil nil t " (fn X)" nil nil) #s(comp-mvar nil nil t nil nil nil) #s(comp-mvar 0 nil nil nil nil nil)) (return #s(comp-mvar nil nil t t nil nil))
As it's clear a new function has been created by this pass.
top-level-run. This will come into play during the load process (more on that later).
Before comp-final
After comp-limplify the following passes are run: comp-ssa
comp-propagate comp-call-optim comp-propagate
comp-dead-code. These have been quickly introduced already and
generally speaking belong to classic compiler theory.
Before entering comp-final this is the content of LIMPLE:
Function: foo <entry> (comment "Lisp function: foo") (set-par-to-local #s(comp-mvar 0 5 nil nil nil nil) 0) (jump bb_0) <bb_0> (comment "LAP op byte-constant") (setimm #s(comp-mvar 1 6 t 0 fixnum nil) 0 0) (jump bb_1) <bb_1> (phi #s(comp-mvar 4 7 nil nil nil t) #s(comp-mvar 4 19 nil nil nil t) #s(comp-mvar 4 4 nil nil nil t)) (phi #s(comp-mvar 3 8 nil nil nil t) #s(comp-mvar 3 18 t "i is: %d" string t) #s(comp-mvar 3 3 nil nil nil t)) (phi #s(comp-mvar 2 9 nil nil nil nil) #s(comp-mvar 2 22 nil nil number nil) #s(comp-mvar 2 2 nil nil nil nil)) (phi #s(comp-mvar 1 10 nil nil nil nil) #s(comp-mvar 1 23 nil nil number nil) #s(comp-mvar 1 6 t 0 fixnum nil)) (comment "LAP TAG 1") (comment "LAP op byte-dup") (set #s(comp-mvar 2 11 nil nil nil t) #s(comp-mvar 1 10 nil nil nil nil)) (comment "LAP op byte-stack-ref") (set #s(comp-mvar 3 12 nil nil nil t) #s(comp-mvar 0 5 nil nil nil nil)) (comment "LAP op byte-lss") (set #s(comp-mvar 2 13 nil nil nil nil) (callref < #s(comp-mvar 2 11 nil nil nil t) #s(comp-mvar 3 12 nil nil nil t))) (comment "LAP op byte-goto-if-nil-else-pop") (cond-jump #s(comp-mvar 2 13 nil nil nil nil) #s(comp-mvar nil nil t nil nil nil) bb_2 bb_3) <bb_3> (comment "LAP TAG 23") (comment "LAP op byte-return") (return #s(comp-mvar 2 13 nil nil nil nil)) <bb_2> (comment "LAP op byte-constant") (setimm #s(comp-mvar 2 14 t bar symbol t) 2 bar) (comment "LAP op byte-stack-ref") (set #s(comp-mvar 3 15 nil nil nil t) #s(comp-mvar 1 10 nil nil nil nil)) (comment "LAP op byte-call") (callref funcall #s(comp-mvar 2 14 t bar symbol t) #s(comp-mvar 3 15 nil nil nil t)) (comment "LAP op byte-discard") (comment "LAP op byte-constant") (comment "optimized out: (setimm #s(comp-mvar 2 17 t message symbol t) 3 message)") (comment "LAP op byte-constant") (setimm #s(comp-mvar 3 18 t "i is: %d" string t) 4 "i is: %d") (comment "LAP op byte-stack-ref") (set #s(comp-mvar 4 19 nil nil nil t) #s(comp-mvar 1 10 nil nil nil nil)) (comment "LAP op byte-call") (callref message #s(comp-mvar 3 18 t "i is: %d" string t) #s(comp-mvar 4 19 nil nil nil t)) (comment "LAP op byte-discard") (comment "LAP op byte-dup") (set #s(comp-mvar 2 21 nil nil nil nil) #s(comp-mvar 1 10 nil nil nil nil)) (comment "LAP op byte-add1") (set #s(comp-mvar 2 22 nil nil number nil) (call 1+ #s(comp-mvar 2 21 nil nil nil nil))) (comment "LAP op byte-stack-set") (set #s(comp-mvar 1 23 nil nil number nil) #s(comp-mvar 2 22 nil nil number nil)) (comment "LAP op byte-goto") (jump bb_1) Function: top-level-run <entry> (comment "Top level") (set-par-to-local #s(comp-mvar 0 1 nil nil nil nil) 0) (call comp--register-subr #s(comp-mvar nil nil t foo nil nil) #s(comp-mvar nil nil t 1 nil nil) #s(comp-mvar nil nil t 1 nil nil) #s(comp-mvar nil nil t "F666f6f_foo" nil nil) #s(comp-mvar nil nil t " (fn X)" nil nil) #s(comp-mvar nil nil t nil nil nil) #s(comp-mvar 0 1 nil nil nil nil)) (return #s(comp-mvar nil nil t t nil nil))
Few notes:
(phi #s(comp-mvar 1 10 nil nil nil nil) #s(comp-mvar 1 23 nil nil number nil) #s(comp-mvar 1 6 t 0 fixnum nil))
This phi is failing to propagate the type number into (comp-mvar 1 10)
because at the moment there's no control over type hierarchy. (See
comp-propagate-insn). It does not change much because now gccemacs
can take advantage only of fixnums in the code generation.
Note also that (comp-mvar 1 23) is a number because it is
computed as result of 1+ and can fall out of fixnums. A type hint
could help here…
Also: The original sequence to call the subr message through the
funcall trampoline was:
(setimm #s(comp-mvar 2 nil nil nil nil nil) 3 message) (comment "LAP op byte-constant") (setimm #s(comp-mvar 3 nil nil nil nil nil) 4 "i is: %d") (comment "LAP op byte-stack-ref") (set #s(comp-mvar 4 nil nil nil nil nil) #s(comp-mvar 1 nil nil nil nil nil)) (comment "LAP op byte-call") (set #s(comp-mvar 2 nil nil nil nil nil) (callref funcall #s(comp-mvar 2 nil nil nil nil nil) #s(comp-mvar 3 nil nil nil nil nil) #s(comp-mvar 4 nil nil nil nil nil)))
This has been modified in:
(comment "optimized out: (setimm #s(comp-mvar 2 17 t message symbol t) 3 message)") (comment "LAP op byte-constant") (setimm #s(comp-mvar 3 18 t "i is: %d" string t) 4 "i is: %d") (comment "LAP op byte-stack-ref") (set #s(comp-mvar 4 19 nil nil nil t) #s(comp-mvar 1 10 nil nil nil nil)) (comment "LAP op byte-call") (callref message #s(comp-mvar 3 18 t "i is: %d" string t) #s(comp-mvar 4 19 nil nil nil t))
This will translate into a direct call to Fmessage. Finally the
unnecessary assignment to slot number 2 has been optimized out
(message return value is unused).
comp-final (comp.el:1811)
Final is the pass that will drive libgccjit "replaying" the LIMPLE content.
The C entry point is Fcomp__compile_ctxt_to_file (comp.c:3102).
Here are its main duties in order:
- Emit symbols and data structures needed to have the code
re-loadable (
emit_ctxt_code). - Define all the functions that are exposed to GCC (see as example
define_CAR_CDR). - Declare all the functions to be compiled (
declare_function) - Define them (
compile_function) into libgccjit IR. - Run all the GCC pipe-line calling
gcc_jit_context_compile_to_file.
compile_function
This is the main entry point for converting LIMPLE into libgccjit IR. It basically iterates over the insns list calling
emit_limple_insn.emit_limple_insnwill then destructure every insn and emit the corresponding statements.Libgccjit can dump a pseudo-C representation of the libgccjit IR. gccemacs ask for that compiling with
comp-debug> 0.Here follows for our function
foo:extern union comp_Lisp_Object F666f6f_foo (union comp_Lisp_Object par_0) { union comp_Lisp_Object[5] local; union comp_Lisp_Object local0; union comp_Lisp_Object local1; union comp_Lisp_Object local2; union comp_Lisp_Object local3; union comp_Lisp_Object local4; struct comp_handler * c; union cast_union union_cast_28; entry: /* Lisp function: foo */ local0 = par_0; goto bb_0; bb_0: /* LAP op byte-constant */ /* 0 */ local1 = d_reloc[(int)0]; goto bb_1; bb_1: /* LAP TAG 1 */ /* LAP op byte-dup */ local[(int)2] = local1; /* LAP op byte-stack-ref */ local[(int)3] = local0; /* LAP op byte-lss */ /* calling subr: < */ local2 = freloc_link_table->R3c_ ((long long)2, (&local[(int)2])); /* LAP op byte-goto-if-nil-else-pop */ /* const lisp obj: nil */ union_cast_28.v_p = (void *)NULL; /* EQ */ /* XLI */ /* XLI */ if (local2.num == union_cast_28.lisp_obj.num) goto bb_3; else goto bb_2; bb_3: /* LAP TAG 23 */ /* LAP op byte-return */ return local2; bb_2: /* LAP op byte-constant */ /* bar */ local[(int)2] = d_reloc[(int)2]; /* LAP op byte-stack-ref */ local[(int)3] = local1; /* LAP op byte-call */ /* calling subr: funcall */ (void)freloc_link_table->R66756e63616c6c_funcall ((long long)2, (&local[(int)2])); /* LAP op byte-discard */ /* LAP op byte-constant */ /* optimized out: (setimm #s(comp-mvar 2 17 t message symbol t) 3 message) */ /* LAP op byte-constant */ /* "i is: %d" */ local[(int)3] = d_reloc[(int)4]; /* LAP op byte-stack-ref */ local[(int)4] = local1; /* LAP op byte-call */ /* calling subr: message */ (void)freloc_link_table->R6d657373616765_message ((long long)2, (&local[(int)3])); /* LAP op byte-discard */ /* LAP op byte-dup */ local2 = local1; /* LAP op byte-add1 */ local2 = add1 (local2, (bool)0); /* LAP op byte-stack-set */ local1 = local2; /* LAP op byte-goto */ goto bb_1; }
Lisp objects are located into an array of Lisp Objects named
d_reloc.Function pointers to call into Emacs are stored into the
freloc_link_tablestructure. Here howFmessageis called:(void)freloc_link_table->R6d657373616765_message ((long long)2, (&local[(int)3]));
Interesting noting what happen to the original
1+call, this is treated differently to the the call tomessage:local2 = add1 (local2, (bool)0);The original call to
Fadd1has been substituted with a call toadd1, a static function defined to libgccjit bydefine_add1_sub1.The substitution happens because the inline emitter for
1+was registered at comp.c:2954 during the first compiler context creation.Here follows the definition of
add1(also dumped into the pseudo-C).static union comp_Lisp_Object add1 (union comp_Lisp_Object n, bool cert_fixnum) { union cast_union union_cast_22; union cast_union union_cast_23; union comp_Lisp_Object lisp_obj_fixnum; entry_block: /* XFIXNUM */ /* XLI */ /* FIXNUMP */ /* XLI */ union_cast_22.ll = n.num >> (long long)0; union_cast_23.i = !(union_cast_22.u - (unsigned int)2 & (unsigned int)3); if ((cert_fixnum || union_cast_23.b) && n.num >> (long long)2 != (long long)2305843009213693951) goto inline_block; else goto fcall_block; inline_block: /* make_fixnum */ /* lval_XLI */ lisp_obj_fixnum.num = ((n.num >> (long long)2) + (long long)1 << (long long)2) + (long long)2; return lisp_obj_fixnum; fcall_block: /* calling subr: 1+ */ return freloc_link_table->R312b_1 (n); }
If the propagation would have been able to prove that
nwas afixnum,add1would have been called withcert_fixnumas true.This is used to signal GCC propagation itself how to optimize the conditions.
Load mechanism
To load the compilation unit:
(load "test.eln")
Fload has been modified and will call Fnative_elisp_load if a
.eln file is found. This will call load_comp_unit.
load_comp_unit will dynlib_sym looking for the following
symbols into our .eln file to perform with them the following
actions:
- Call
freloc_hash(function returning a string to signfreloc_link_table) and check its content. Fail in case it does not match. - Set
current_thread_reloc(static pointer holding the address ofcurrent_thread). - Set
pure_reloc(static pointer holding the address ofpure). - Set
freloc_link_table(static pointer to a structure of function pointers in use to call from native compiled functions into Emacs primitives). - Call
text_data_reloc(function returning a string) andreadthe vector of Lisp objects used by native compiled function. In this case:
[0 nil bar message "i is: %d" foo 1 "F666f6f_foo" " (fn X)" t consp listp]
- Set
d_reloc(static array of Lisp objects in use by compiled functions).
After this top_level_run is called. Here's its pseudo source:
extern union comp_Lisp_Object top_level_run (union comp_Lisp_Object par_0) { union comp_Lisp_Object[1] local; union comp_Lisp_Object local0; struct comp_handler * c; union cast_union union_cast_29; union cast_union union_cast_30; union cast_union union_cast_31; entry: /* Top level */ local0 = par_0; /* const lisp obj: foo */ /* 1 */ union_cast_29.v_p = (void *)0x6; /* 1 */ union_cast_30.v_p = (void *)0x6; /* const lisp obj: "F666f6f_foo" */ /* const lisp obj: " (fn X)" */ /* const lisp obj: nil */ union_cast_31.v_p = (void *)NULL; /* calling subr: comp--register-subr */ (void)freloc_link_table->R636f6d702d2d72656769737465722d73756272_comp__register_subr (d_reloc[(long long)5], union_cast_29.lisp_obj, union_cast_30.lisp_obj, d_reloc[(long long)7], d_reloc[(long long)8], union_cast_31.lisp_obj, local0); /* const lisp obj: t */ return d_reloc[(long long)9]; }
top_level_run will perform all the expected modifications to the
enviroment by the load of the .eln file.
In this case it is just calling back into Emacs
Fcomp__register_subr (comp.c:3294) asking to register a subr named
foo (no other top level forms were present).
Since then foo is defined as subr, called and treated as that.
Primitive subrs and subrs from native compiled code are
distinguishable using the predicate subr-native-elisp-p
(data.c:870).
Here downloadable the full output of the pseudo C-code test.c
Update 2
This update comes with some pretty major technical changes and features.
New function link table ABI
Going in the direction of having to load many eln files I thought
it was good to have just one single function link table. This
structure is the array of function pointers used by the native
compiled code to call Emacs C primitives and functions supporting
the run-time.
In the first proposed prototype this structure was defined and
compiled differently for every eln file. This means that every eln
had his own version of it including just and only the needed
pointers.
If this is an advantage in terms of memory usage and locality for
loading few eln it does not scale up very well. It also pulls in
a circular dependency on the compiler with advice.el that is now
removed and, generally speaking, the mechanism is quite simplified.
To produce a single function link table I needed a list of all
defined subrs. defsubr has been modified to cons the list with
that. This list is then used both by the compiler and by the load
mechanism. It survives bootstrap and restarts in general being
dumped as a conventional lisp structure.
The last missing caveat of this is hashing and verifying at load
time that the eln file being loaded is complaint with the running
system. This is to be done.
Garbage collector support
The expected behavior for this to have the eln file unloaded
automatically when this is not in use anymore. This is achieved
with the introduction of a new kind of object the native
compilation unit.
The mechanism is quite simple. Every native lisp function has a
reference to the original compilation unit. When this is not
reachable anymore (because all functions defined into it got
redefined) it is unloaded with a dlclose (or equivalent) while
the object is garbage collected.
Image dump
This gave me quite some thinking. I guess some story telling will explain some of the rationale that lead to the current implementation. The two main options on the table were:
Linker approach.
Generating code with something that is essentially a C tool-chain using the system linker would have appeared as the first option.
Still was unclear to me how to cope with side effects that are not barely function definitions. I guess some modification in the actual code-base would have been necessary.
Also making something future proof for subsequent dumps of the Lisp image looked quite challenging.
Including compiled functions into the image dump.
Including single functions into the dump image had its difficulties too. Essentially I came to the conclusion that trying to break in functions an already compiled and linked shared library, store and then reload functions would translate into: having to parse the elf, re-implement part of the loader, make assumptions on the implementation etc… In short searching for troubles.
In my mind I formed the opinion that breaking the compilation unit
in pieces was a mistake and I just had to cope with that. I then
came up with the plan of storing each full eln file into the
image dump.
This could work but the issue is that loading a shared library that resides into memory and not in a file came up not being completely trivial.
dlopen takes a filename as a parameter and I guess (I could be
wrong) the secret reason for that is that the dynamic linker is
just a program… and yes! In Unix programs work on files…
I then found about memfd_create as possible work-around. This a
syscall present in recent Linux kernel that let you create a file
descriptor from a piece of your user space memory without having to
do any real file copy or real file-system access. The file will
appear in some /proc sub-folder.
I wasn't very keen on this option because of it being non portable
but it looked like the last option and some alternative equivalent
to memfd_create seemed to exists for other non Linux kernels.
I was already half way into the implementation when I stepped back and wanted to rethink to the problem as a whole.
Why the Emacs dump image mechanism was created?
Startup time is the motivation for that.
The fact that the result is a single file (or two in case of the portable dumper) is, I think, just a (nice) side effect.
Having a single file to load is faster mainly because objects in it
are serialized in a binary format and don't need to go through the
reader (as it is the case for elc files).
But thinking about functions into eln files are already
serialized being compiled into machine code and the action of
calling dlsym is just doing a lookup asking for the entry point
address into memory.
So what's the motivation of dumping if we have already eln files?
Couldn't we just load them?
No. This would be sub optimal because still in the eln file
format there is a piece of data left that goes through the reader
during its load. These are the objects used by functions. We are
talking about a vector that is the per compilation unit aggregation
of the original constant vectors. And last but not least is
absolutely nice to have a system where all the enviroment state is
dump-able.
Given all these constraints and thoughts my final solution is:
- store into the
compilation unitLisp object (already defined for the gc support) a reference to theelnfile originally loaded. - at dump-time just dump the
compilation unitobject but do not include theelnfile content in the dump file. - at
compilation unitload time (during relocation to use precise pdump nomenclature) revive it with a dlopen on the originaleln. - after all compilation units have been relocated proceed with
native functions relocating all function pointer doing
dlsyminto the compilation unit.
The good side effect of this mechanism is that the data vector does not have to be read by the reader because is naturally dumped and restored by the pdumper infrastructure.
Am I cheating then? Maybe, but I think this solution is quite
sound. Nevertheless in case having a unique file is an hard
requirement falling back to an memfd_create like solution would be
just an incremental step on the implemented mechanism.
Here again is missing a sanity check to ensure the eln file being
reloaded has not been changed. To be done.
Bootstrap
The standard bootstrap process is not radically changed.
Essentially where elc were compiled eln files are compiled too.
Note that the reason why elc compilation is still necessary is
because the native compiler does not support dynamic scope.
When the native compiler fails because of this, Emacs will have the
elc file at disposal for load. A cleaner solution would be to
distinguish between dynamic and lexical scoped files while defining
compilation targets but… good for now.
I've taken few measures of time regarding the full bootstrap process from a clean repository (including C compilation) on my dual core laptop.
| Emacs baseline | gccemacs | gccemacs |
|---|---|---|
| comp-speed 0 | comp-speed 2 | |
| ~8min | ~25min | ~6h |
I've left speed 0 as default for now.
I tried to perform some measurement on startup time using:
time ~/emacs/build/src/emacs -batch
But on my system the difference looks within the noise level and the startup time for both is ~0.1s.
Similar result trying to measure the difference of time needed to
(require 'org).
Function disassembly
I've added an initial support to the disassemble function for
native compiled code. This is what it looks like disassembling on
my machine bubble-no-cons from elisp-benchmarks.
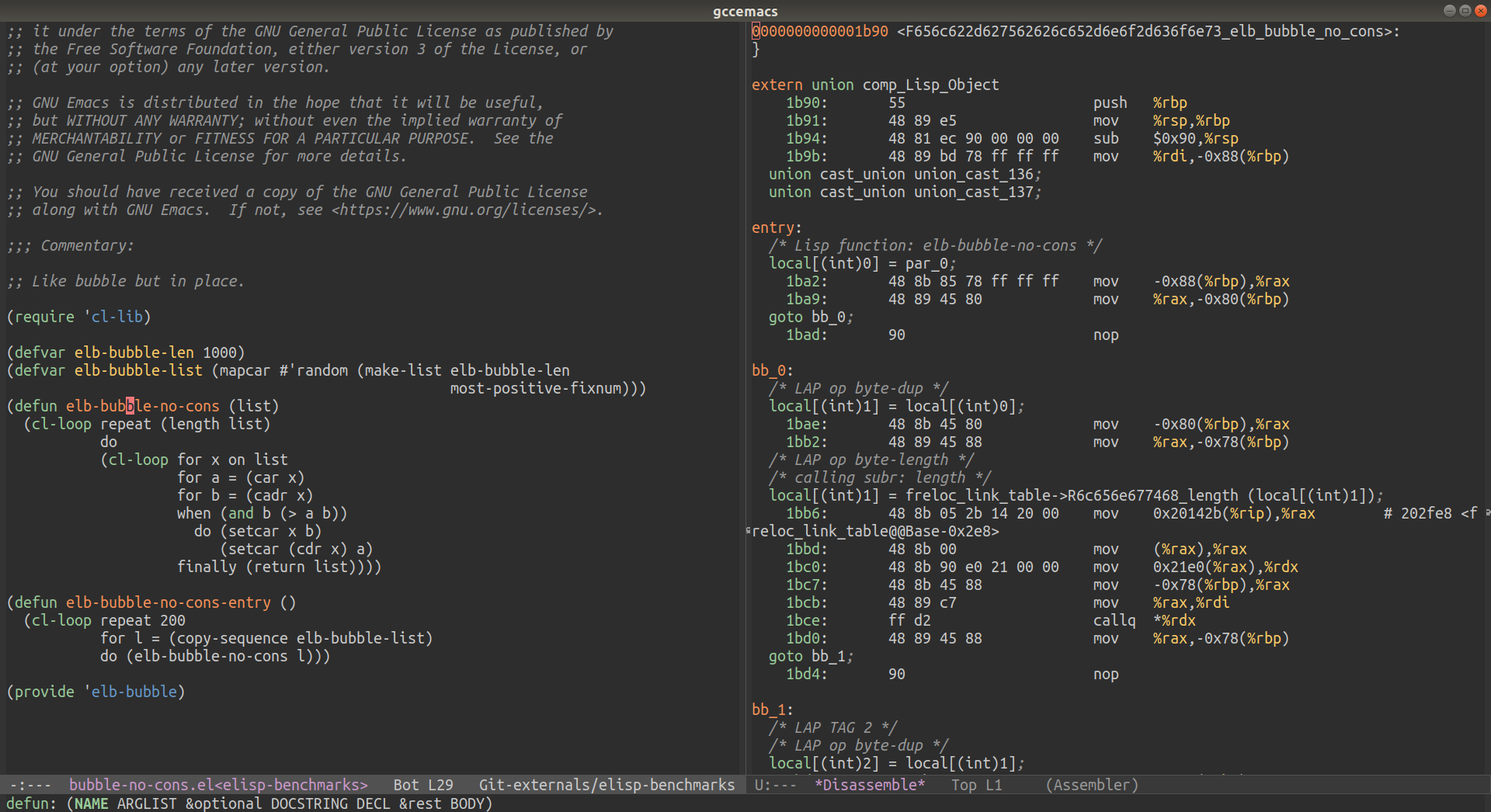{kind=link}
Note some pseudo C code and comments are intermixed with the
assembly by objdump. This is because the function was compiled
using comp-debug 1 therefore some debug symbols are emitted to
ease the compiler debug.
Update 1
I've implemented the support for docstrings and interactive functions.
As a consequence as of today all lexically scoped Elisp functions can be native compiled with no exceptions.
Ex: this is the output I get for C-h f org-mode:
org-mode is native compiled Lisp function in ‘org.el’. (org-mode) Parent mode: ‘outline-mode’. Probably introduced at or before Emacs version 22.1. Outline-based notes management and organizer, alias "Carsten’s outline-mode for keeping track of everything." Org mode develops organizational tasks around a NOTES file which contains information about projects as plain text. Org mode is ...
As expected clicking on org.el correctly drives me to the original location in the source code.
Being native compiled org-mode function cell satisfies subrp.
(subrp (symbol-function #'org-mode)) => t
I'll try to keep the /master branch as the one with the most
updated working state for the project.
Please fire a mail to akrl AT sdf DOT org in case you find it to
be broken.
gccemacs
gccemacs is a modified Emacs capable of compiling and running
Emacs Lisp as native code in form of re-loadable elf files. As the
name suggests this is achieved blending together Emacs and the gcc
infrastructure.
The scope of this project is to experiment and discuss the proposed compiler design on the emacs-devel mailing list (part1, part2).
I've no current plan to have this as a long standing maintained out of tree Emacs fork.
Main tech goals for gccemacs are:
- show that elisp run-time can be considerably improved by the proposed compiler approach.
- test for a viable and non disruptive way to have a more capable lisp implementation.
Having elisp self-hosted would enable not only a faster environment but also an easier Emacs to be modified requiring less C code to be written.
The actual code can be found here:
Not a jitter
gccemacs is not a jitter. The compilation output (.eln files)
are elf files suitable for being reloaded between different
sessions.
I believe this solution has advantages over the jitter approach not having the duty to recompile at every start-up the same code.
This is a key advantage especially for an application sensitive to the start-up time as Emacs is. Moreover more time can be spent for advanced compile time optimizations.
Some complication to have the system re-loadable exists but is worth paying.
A further advantage of this solution is the potential for reducing load-time. Optimizing for load time should be further investigated.
libgccjit
Plugging into the gcc infrastructure is done through libgccjit.
Despite what the name suggest libgccjit is usable not just for
making jitters but for any other kind of compiler.
libgccjit can be seen as a way to drive the gcc in form of shared
library using function calls. In other words this is probably the
'cheapest' way to write what is technically named a front-end in
compiler jargon.
Usage
Which libgccjit
libgccjit was added to gcc 5 thanks to David Malcolm.
gccemacs should not be using any recently added entry point
therefore in theory any libgccjit should be fine. BUT:
- gcc 9 was affected by PR91928 https://gcc.gnu.org/bugzilla/show_bug.cgi?id=91928. I fixed it for the trunk and did the back port into the 9 branch so as of revision 276625 also gcc 9 should be functional again. gcc 8 and earlier should not be affected but I had no time to do any serious test with them.
- gcc 7 shipped with Ubuntu 18.04 was reported not to pass
gccemacstests.
Consider these information if you want to try the libgccjit
shipped by your distribution.
I suggest a recent gcc 9 if you are going to compile. Please
report any success or failure of using gccemacs with different
versions of gcc otherwise.
libgccjit compilation instructions and doc is here:
https://gcc.gnu.org/onlinedocs/jit/index.html
Compilation
Once libgccjit is installed a normal autogen.sh + configure +
make should do the job for gccemacs.
Once compiled, the native compiler tests can be run with:
~/emacs/src/emacs -batch -l ert -l ~/emacs/test/src/comp-tests.el -f ert-run-tests-batch-and-exit
(adjust path accordingly).
Entry points
gccemacs adds two main entry points for compilation:
native-compilenative-compile-async
Some special variables influence compilation most notably
comp-speed. This can range from 0 to 3 as in Common Lisp style.
See the doc for details.
Once a compilation unit is compiled the output is an .eln file.
This similarly to an .elc and can be loaded by require or
manually.
A lisp file can be compiled as follows:
(native-compile-async "file.el")
Once the compilation completes, the produced file.eln can be
loaded conventionally.
Please note that file.el has to be lexically bound in order to
be compiled.
A native compiled function foo should then present on a
describe-function something like:
foo is a built-in function in ‘C source code’.
A more common usage is to compile more files or entire folders.
The following example will compile asynchronously all the
installed packages (the number 4 is equivalent to -j4 for make).
(native-compile-async "~/.emacs.d/elpa/" 4 t)
Progress can be monitored into the *Async-native-compile-log*
buffer.
A foreword about why optimizing outside gcc
While I'm writing I recall few (I think good) reasons why I decided to replicate some optimizing compiler algorithmics outside gcc:
- The gcc infrastructure has no knowledge that a call to a
primitive (say
Fcons) will return an object with certain tag bits set (in this case say is a cons). The only feasible way to inform it would be to use LTO but I've some doubts this would be practical for this application. - I decided to layout the activation frame with an array to hold lisp objects local to the function. This not to have to move and store these whenever a call by ref is emitted. To avoid having the compiler clobber all the local objects in the activation frame every time one of these function calls is emitted, I decided to lift the objects that are not involved by this kind of calls in the equivalent of conventional automatic local variables. To do this I need to propagate the ref property within the control flow graph.
- Gcc infrastructure has no knowledge of what lisp pure functions are therefore this is a barrier for its propagation.
- Gcc does not provide help for boxing and unboxing values.
- The propagation engine can be used for giving warnings and errors at compile time.
Internals
gccemacs compilation process can be divided into 3 main phases:
byte-compilation
This is the conventional Emacs byte compilation phase, is needed because the output of the byte compiler is used as input for the following phase.
middle-end
Here the code goes through different transformations. This is implemented into
lisp/emacs-lisp/comp.elback-end
This defines inliner and helper functions and drives
libgccjitfor the final code generation. It is implemented insrc/comp.c.
Passes
The gccemacs native compiler is divided in the following passes:
spill-lap:The input used for compiling is the internal representation created by the byte compiler (LAP). This is used to get the byte-code before being assembled. This pass is responsible for running the byte compiler end extracting the LAP IR.
limplify:The main internal representation used by
gccemacsis called LIMPLE (as a tribute to the gcc GIMPLE). This pass is responsible for converting LAP output into LIMPLE. At the base of LIMPLE is the structcomp-mvarrepresenting a meta-variable.(cl-defstruct (comp-mvar (:constructor make--comp-mvar)) "A meta-variable being a slot in the meta-stack." (slot nil :type fixnum :documentation "Slot number. -1 is a special value and indicates the scratch slot.") (id nil :type (or null number) :documentation "SSA number when in SSA form.") (const-vld nil :type boolean :documentation "Valid signal for the following slot.") (constant nil :documentation "When const-vld non nil this is used for holding a value known at compile time.") (type nil :documentation "When non nil indicates the type when known at compile time.") (ref nil :type boolean :documentation "When t the m-var is involved in a call where is passed by reference."))
As an example the following LIMPLE insn assigns to the frame slot number 9 the symbol
a(found as third element into the relocation array).(setimm #s(comp-mvar 9 1 t 3 nil) 3 a)
As other example, this is moving the 5th frame slot content into the 2nd frame slot.
(set #s(comp-mvar 2 6 nil nil nil nil) #s(comp-mvar 5 4 nil nil nil nil))
At this stage the function gets decomposed into basic blocks being each of these a list of insns.
In this phase the original push & pop within the byte-vm stack is translated into a sequence of assignments within the frame slots of the function. Every slot into the frame is represented by a
comp-mvar. All this spurious moves will be eventually optimized. It is important to highlight that doing this we are moving all the push and pop machinery from the run-time into the compile time.ssaThis is responsible for porting LIMPLE into SSA form. After this pass every
m-vargets a unique id and is assigned only once.Contextually also phi functions are placed.
propagateThis pass iteratively propagates within the control flow graph for each m-var the following properties: value, type and if the m-var will be used for a function call by reference.
Propagate removes also function calls to pure functions when all the arguments are or become known during propagation.
NOTE: this is done also by the byte optimizer but propagate has greater chances to succeeds due to the CFG analysis itself.
call-optimThis is responsible for (depending on the optimization level) trying to emit call that do not go through the funcall trampoline.
Note that after this all calls to subrs can have equal dignity despite the fact that they originally got a dedicate byte-op-code ore not.
Please note also that at speed 3 the compiler is optimizing also calls within the same compilation unit. This saves from the trampoline cost and allow gcc for further in-lining and propagation but makes this functions non safely re-definable unless the whole compilation unit is recompiled.
dead-codeThis tries to remove unnecessary assignments.
Spurious assignment to non floating frame slots cannot be optimized out by gcc in case the frame is clobbered by function calls with the frame used by reference so is good to remove them.
finalThis drives LIMPLE into
libgccjitIR and invokes the compilation. Final is also responsible for:- Defining the inline functions that gives gcc visibility on the lisp implementation.
- Suggesting to them the correct type if available while emitting the function call.
- Lifting variables from the frame array if these are to be located into the floating frame.
Compiler hints
Having realized it was quite easy to feed the propagation engine with additional information I've implemented two entry points.
These are:
comp-hint-fixnumcomp-hint-cons
As an example this is to promise that the result of the following expression evaluates to a cons:
(comp-hint-cons x)
Propagation engine will use this information to propagate for all
the m-vars influenced by the evaluation result of (comp-hint-cons
x) in the control flow graph.
At comp-speed smaller then 3 the compiler hints will translate
into assertions verifying the property declared.
These low level primitives could be used to implement something
like the CL the.
Type checks removal
This section applies to the (few) functions exposed to the gcc,
namely: car, cdr, setcar, setcdr, 1+, 1-, -
(Fnegate).
At comp-speed 3 type checks will not be emitted if the
propagation has proved the type to be the expected one for the
called function.
Debugging the compiler
The native compiler can be debugged in several ways but I think the
most propaedeutic one is to set comp-debug to 1. In this way the
compiler will depose a .c file aside the .eln.
This is not a true compilable C file but something sufficiently
close to understand what's going on. Also debug symbols are
emitted into the .eln therefore is possible to trap or step into
it using gdb.
Note that comp-debug set to 1 has a negative impact on compile
time.
Quick performance discussion
In order to have something to optimize for and measure we have put together a small collection of elisp (nano and non) benchmarks.
https://gitlab.com/koral/elisp-benchmarks
The choice of the benchmarks and their weight is certainly very arbitrary but still… better than nothing.
All benchmarks can be considered u-benchmarks except nbody and
dhrystone. Worth nothing that these last two has not been tuned
specifically for the native compiler.
On the machine I'm running (i7-6600U) the latest performance figure I've got is the following:
| name | byte-code | native-bench | native-all | native-all vs. |
|---|---|---|---|---|
| (sec) | (sec) | (sec) | byte-code | |
| bubble | 30.44 | 6.54 | 6.29 | 4.8x |
| bubble-no-cons | 42.42 | 10.22 | 10.20 | 4.2x |
| fibn | 39.36 | 16.96 | 16.98 | 2.3x |
| fibn-rec | 20.64 | 8.06 | 7.99 | 2.6x |
| fibn-tc | 19.43 | 6.33 | 6.89 | 2.8x |
| inclist-tc | 20.43 | 2.16 | 2.18 | 9.4x |
| listlen-tc | 17.66 | 0.66 | 0.70 | 25.2x |
| inclist-no-type-hints | 45.57 | 5.60 | 5.81 | 7.8x |
| inclist-type-hints | 45.89 | 3.67 | 3.70 | 12.4x |
| nbody | 112.99 | 23.65 | 24.44 | 4.6x |
| dhrystone | 112.40 | 64.67 | 47.12 | 2.4x |
| tot | 507.23 | 148.52 | 132.3 | 3.8x |
Column explanation:
byte-codebenchmark running byte compiled (baseline).native-benchbenchmark running native compiled on a non native compiled emacs.native-allbenchmark running with the benchmark itself and all emacs lisp native compiled.
All benchmarks has been compiled with comp-speed 3 while the
Emacs lisp for the native-all column with comp-speed 2.
Here follows a very preliminary and incomplete performance discussion:
bubble bubble-no-cons fibn u-benchmarks shows fair results
with no specific tuning.
Recursive benchmarks (suffixed with -rec or -tc) shows an
enormous uplifts most likely dominated by much faster calling
convention. Note that no TCO here is performed.
inclist-no-type-hints and inclist-type-hints shows a
considerable performance uplift just due to type checks being
optimized out thanks to the information coming from the type hints.
nbody is ~4.6x faster with no lisp specific optimization
triggered. This benchmark calls only primitives (as all previous
u-benchs) therefore having all Emacs native compiled does not gives
any advantage. Probably intra compilation unit call optimization
plays a role into the result.
On the other side dhrystone benefits quite a lot from the full
Emacs compilation having to funcall into store-substring and
string>.
Hope this indicates a potential for considerable performance benefits.
Status and verification.
A number of tests is defined in comp-tests.el. This is including
a number of micro tests (some of these inherited by Tom Tromey's
jitter) plus a classical bootstrap test were the compiler compiles
itself two times and the binary is compared.
A couple of colleagues and me are running in production gccemacs
with all the Emacs lexically scoped lisp compiled plus all the elpa
folder for each of our setups.
While I'm writing this I've loaded on this instance 18682 native
compiled elisp functions loaded from 669 .eln files.
So far this seems stable.
Current limitations
The following limitations are not due to design limitations but just the state of a "work in progress":
- Only lexically scoped code is compiled.
Interactive functions are included into eln files but as byte-compiled.(Update 1)No doc string support for native compiled functions.(Update 1)- Limited lisp implementation exposure: Just few function are
defined and exposed to gcc:
car,cdr,setcar,setcdr,1+,1-,-(Fnegate). This functions can be fully in-lined and optimized. Type propagation:
Very few functions have a return type declared to the compiler (see
comp-known-ret-types). Moreover type propagation can't relay on the CL equivalent ofsub-type-p.Garbage collection support has to be done:(Update 2)Once a.elnfile is loaded it is never unloaded even if the subrs there defined are redefined.No integration with the build system:(Update 2)No native compilation is automatically triggered by the build process.Native compiler is not re-entrant:
Just top level functions are native compiled, the others (lambda included) are still kept as byte-code.
Further compiler improvements
Better lisp exposure
As mentioned in the previous paragraph the lisp machinery exposed to the gcc infrastructure is at this point quite limited and should be improved.
Unboxing
Introducing the unboxing mechanism was considered out of scope for this investigation but is certainly possible to extend the current infrastructure to have it. Unboxing would have a big impact on performance. Combined with compiler hints should be possible to generate efficient code closing some more gap with C (in some cases probably all).
Long term
- Further improving load time performance using the portable dumper for object de/serialization within elns (currently the print read mechanism is in use).
- Provide better compile time warning and errors relying on the propagation engine?
- The real final goal would be to be able to assemble the Emacs image having the native compiled functions replacing all the byte-compiled one out of the box. EDIT: See (Update 2)!
Final word
All of this is very experimental. Take it (at your risk) as what it is, a proof of concept.
Feedback is very welcome.